reproduction: Vision Transformer on MNIST
对 ViT (ICLR 2021) 进行了简单复现,在 MNIST 训练集上训练了 50 个 epoch,在测试集上的准确率高于 98%。
模型架构
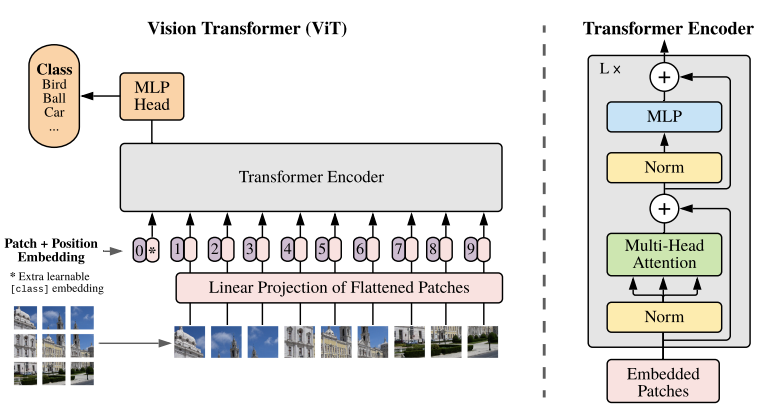
分割图片并线性投影
以一个 1x28x28 (Channel = 1, H = W = 28)大小的图片为例。
设定 patch 尺寸为 4x4,对每一个 patch,我们把它转化成一个 embedding,此处我把 embedding 的维度设置为了和原图片相当的大小,相当于直接拉平了,并没有往高维度投影。即 1x28x28 -> 1x7x7x16,再 reshape 成 1x49x16。通过这样的线性投影变换,1x28x28 大小的图片被转化为 49x16 大小的 token 序列,即共有 49 个 token,每个 token 的 embedding 长度为 16。
实际上,ViT 原论文没有用 linear 层来实现线性投影,而是直接用了一个 Conv2d 层,在本质上它们是完全等价的,所以我在这里也直接用一个卷积层实现线性投影逻辑:
self.conv=nn.Conv2d(
in_channels=1,
out_channels=self.patch_size**2, # 此处可以更改成更高的维度,我在这里没有往更高维度投影。
kernel_size=self.patch_size,
padding=0,
stride=self.patch_size
)
添加 cls token
cls token 是一个特殊的 token,它会被拼接到线性投影后的序列的头部,最终用来代表整个图像的全局特征。
添加 pos embedding
pos embedding 是随机初始化的、可学习的 embedding。它直接加到每一个 token 上,形成最终的输入。
Transformer Encoder
将经过以上步骤处理好的图片数据传入 transformer encoder 层(此处可以叠加多个 encoder)。
MLP head
只取 0 号 token 位置的输出,即 cls token 位置的输出,经过 mlp head,得到最终分类结果(类别长度的 logits)。例如,对于一个识别手写数字 0-9 的 ViT,如果我们输入了 5 张手写数字图片(5x1x28x28),最终会得到 5x10 大小的输出,第二维度为该图片为 0-9 对应数字的 logit。
思考
一个小型的 toy ViT 就可以在 MNIST 数据集上获得不错的效果。但问题在于,CNN 架构在图片分类,以及和视觉相关的各项任务上,表现都已经很好了,而且,由于 CNN 架构自带归纳偏置(局部性、平移等变性),在小规模数据集上,它的表现甚至比 ViT 还要好。
那么 ViT 这种架构的意义在何处呢?
实际上,ViT 的核心价值,不在于”图片分类比 CNN 准多少”,而在于它把视觉问题纳入了 Transformer 的统一框架。在 ViT 之前,Transformer 架构已经可以说统治了 NLP 领域,但在 CV 领域,CNN 仍然是主要的设计哲学。而 ViT 的出现证明了:图像也可以当成序列来处理,Transformer 同样适用于视觉。
如此一来,统一架构的多模态大模型才真正成为了可能:视觉和语言用同一套 Transformer 骨干,特征空间可以对齐;同一套代码、同一套训练技巧,可以同时用在视觉和语言任务上,视觉也能开始享受 Scaling law 所带来的大规模预训练红利。
一言以蔽之,ViT 的价值不主要是”一个更好的图片分类器”,而是打开了用统一架构处理多种模态的大门,是现在多模态 AI 时代的重要基础之一。