reproduction: MiniOneRec
MiniOneRec
MiniOneRec 是第一个开源的生成式推荐系统框架。它成功地将 LLMs 应用于推荐系统,在公开数据集上验证了推荐系统也可以获益于 scaling law。整个训练过程由 Semantic Encoding,SFT, GRPO 三部分构成,三个阶段环环相扣:编码层提供结构化的商品表示,SFT 建立基础的推荐能力与语义对齐,GRPO 则在此基础上进一步优化排序质量和候选多样性。
在此,不能不提及快手在 2025 年发布的 OneRec,OneRec 是快手为亿级用户和视频多模态内容设计的完整工业系统,在多项推荐任务相关指标上取得了非常显著的提升,并且已经被正式部署在快手的多个应用上。 OneRec Technical Report 详细介绍了 OneRec 的架构设计和实验结果,但并未对源代码和数据集进行开源,且对算力的要求巨大,因此个人很难进行复现。在此背景下,MiniOneRec 随即诞生,它开源了训练数据集和模型框架,验证了生成式推荐系统确实能获益于 scaling law。
但必须指出,MiniOneRec 是面向学术开源场景的简化实现,其定位是”Mini”。在整个架构设计上,它和 OneRec 框架存在差异,并非对 OneRec 的完整复现。但是,我们仍然可以通过 MiniOneRec 了解生成式推荐系统的设计哲学,并且这一整套从训练 RQ-VAE 编码器、扩充 LLM tokenizer,到对 LLM 做 SFT、GRPO 的全流程,能够帮助我们熟悉大模型微调相关的各项技术。
模型架构
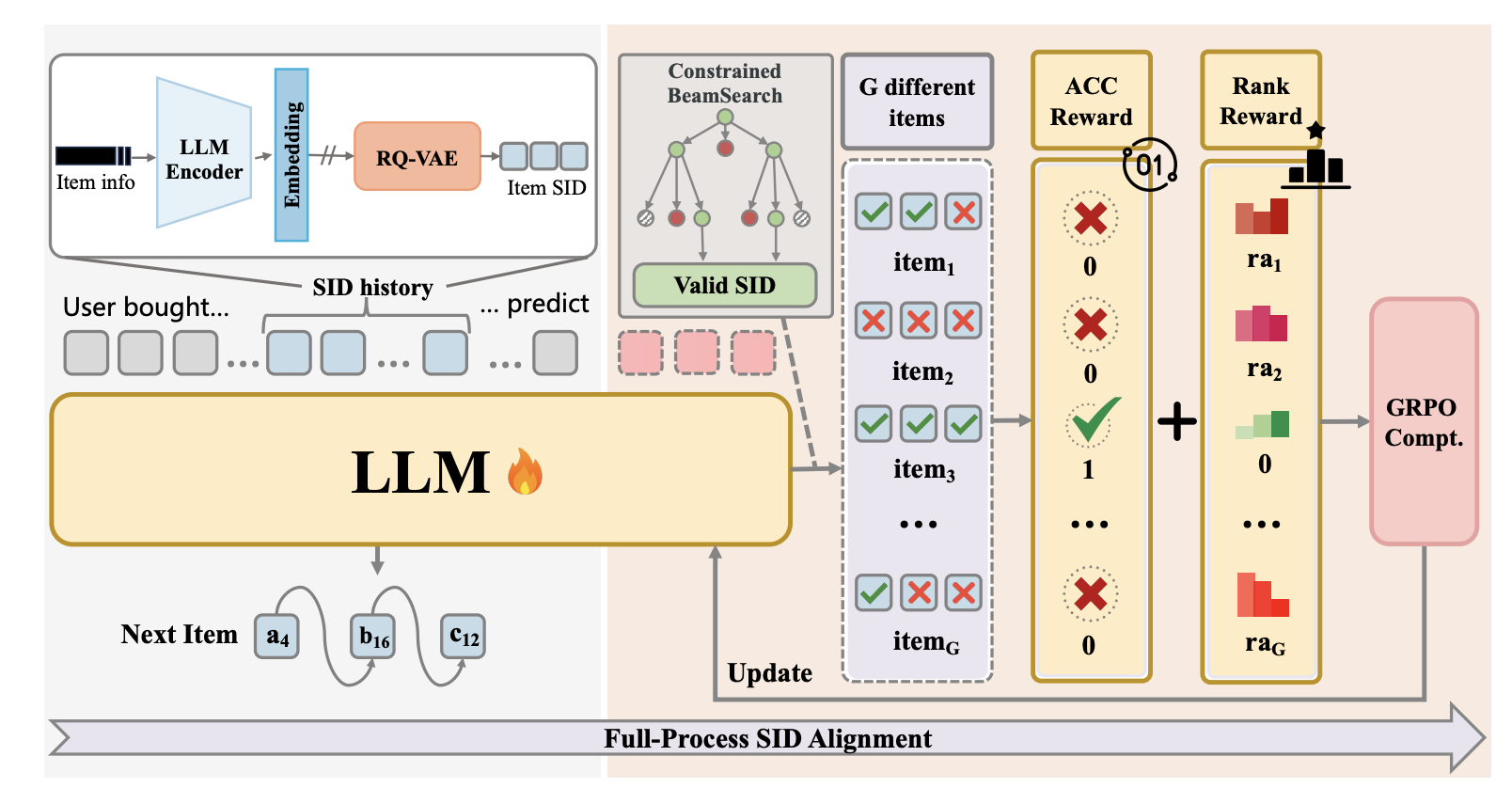
MiniOneRec 的整体流程可以分为三个阶段:
-
商品编码(左上角) Item info 经过 LLM Encoder 生成语义 Embedding,再经 RQ-VAE 量化为三个离散 token(a、b、c)组成的 Item SID,构建商品的结构化表示。
-
LLM 推理与生成(左侧主体) 以用户的 SID 历史序列作为输入,由一个 Decoder-only LLM 自回归地预测下一个商品的 SID在 RL 阶段,通过 Constrained Beam Search 同时生成 G 个不同的候选商品,并保证每个输出都是合法的 Valid SID。
-
奖励计算与 GRPO 更新(右侧) 对 G 个候选商品分别计算两种奖励并相加:
- ACC Reward:二值奖励,命中目标商品得 1 分,否则 0 分
- Rank Reward:排序感知奖励,对排在前面的错误负样本施加更强惩罚 两者之和送入 GRPO 进行策略梯度更新。
值得注意的是,训练时保持贯穿全程的 Full-Process SID Alignment,即 SID 与自然语言之间的对齐任务在 SFT 和 RL 两个阶段始终保持,确保 LLM 的世界知识持续与 SID 空间绑定,而非只在某一阶段对齐。
商品编码
在传统推荐系统中,每件商品直接对应一个随机初始化的 Embedding 向量,模型通过用户-商品交互信号来学习这个向量的值,商品的语义内容(标题、描述等)往往是辅助特征,而非主体。这种设计的问题在于:Embedding 表纯粹依赖协同过滤信号,无法捕捉商品间的语义相似性,且参数量随商品数量线性增长,难以扩展,更无法享受 LLM 的 scaling 红利。
生成式推荐的核心思路转变在于:让语言模型直接”说出”下一个商品是什么。但语言模型只能生成 token 序列,无法直接输出一个商品 ID,因此必须先把每件商品压缩成一段离散的 token 序列(即 SID),让语言模型的生成空间与商品空间对齐。商品编码做的正是这件事——它是连接”商品世界”与”语言模型生成空间”的桥梁,没有它,自回归生成推荐就无从谈起。
MiniOneRec 选择了 RQ-VAE 作为编码器。 TIGER 第一次把 RQ-VAE 引入推荐系统,RQ-VAE 之所以被选用,是因为它能将语义向量以层次化、紧凑的方式压缩为少量离散 token,既保留了语义信息,又控制了词表规模,使得语言模型的生成是可行且高效的。
下面,详细解释一下 MiniOneRec 中 RQ-VAE 的训练过程:
- 第一步:文本输入 对每件商品 $i$,将其标题和描述拼接为一段文字,作为编码的原始输入。
- 第二步:语义向量提取 将拼接后的文本送入冻结的文本编码器(MiniOneRec 中使用 Qwen3-Embedding-4B),输出 $d$ 维语义向量: $x \in \mathbb{R}^d$ ,编码器权重在训练中保持不变。
- 第三步:残差量化(核心) RQ-VAE 的量化过程共 $L=3$ 层,每层有一个独立的码本 $\mathcal{C}_l$,每个码本含 $K=256$ 个码字。 初始化:令残差 $r_0 = x$ 对每一层 $l$($l = 0, 1, 2$),执行:
-
查找最近码字:在码本 $\mathcal{C}_l$ 中找到与当前残差 $r_l$ 距离最近的码字索引:
\[c_l = \arg\min_k \|r_l - e_k^{(l)}\|_2\] -
更新残差:用当前残差减去选中的码字向量,得到下一层输入:
\(r_{l+1} = r_l - e_{c_l}^{(l)}\) 三层完成后,商品 $i$ 被表示为三个离散索引 $(c_0, c_1, c_2)$,即其 SID。码本大小为 $256^3 = 2^{24}$,足以覆盖数亿量级的商品目录。
-
-
第四步:重建与训练 量化后的潜变量通过各层码字向量相加恢复:
\[z_q = \sum_{l=0}^{L-1} e_{c_l}^{(l)}\]再经解码器 $D(\cdot)$ 重建原始向量:
\[\hat{x} = D(z_q)\]训练损失由重建损失与 RQ 正则项组成:
\[\mathcal{L}(x) = \underbrace{\|x - \hat{x}\|_2^2}_{\text{重建损失}} + \underbrace{\sum_{l=0}^{L-1}\left(\|\text{sg}[r_l] - e_{c_l}^{(l)}\|_2^2 + \beta\|r_l - \text{sg}[e_{c_l}^{(l)}]\|_2^2\right)}_{\text{RQ 正则项}}\]其中 $\text{sg}[\cdot]$ 为 stop-gradient 算子,$\beta$ 控制 commitment loss 强度。正则项驱使码字向残差靠拢(第一项),同时让残差向码字靠拢(第二项),防止编码器输出漂移过远。
从直觉上理解, 可以把 RQ-VAE 类比为一种”粗到细”的近似:第一层码字负责捕捉语义的主要方向,后续层逐步修正前一层留下的误差,三层合力才完整描述商品语义。这也是为什么 SID 是三个 token 的层次结构,而非一个扁平的单一 ID。
SFT
SFT 阶段的核心目的有两个:一是让 LLM 学会根据用户历史序列预测下一个商品的 SID(推荐能力);二是将 LLM 内部的世界知识与 SID 空间建立双向映射(对齐能力)。两者联合训练,共同构成 RL 阶段的起点。
在进入训练之前,需要将 RQ-VAE 生成的所有 SID token 添加到 LLM 原始词表中。具体做法是追加一个三层码本,每层 256 个专用 token,这些 token 被视为不可分割的原子单元,不会被分词器拆成子词。这一步是对齐的物质基础——LLM 必须先”认识”SID,才能对其进行读写。
SFT 阶段包含两大组任务,同时混合训练:
-
推荐任务(Recommendation Tasks)
① 生成式检索(主任务) 输入用户按时间排序的 SID 交互历史,指令为”推荐下一个商品”,模型输出下一个商品的 SID。这是推荐系统的核心任务,直接对应最终评估指标。
Input: 用户历史 <a_13><b_197><c_1>, <a_52><b_17><c_113>, ... Can you predict the next possible item? Output: <a_13><b_72><c_149>② 非对称商品预测 两个互补的子任务,强制模型在文本空间和 SID 空间之间切换:
- 给定文本形式的历史(商品标题列表),预测下一个商品的 SID
- 给定SID 形式的历史,预测下一个商品的文本标题 这两个任务的意义在于:迫使模型建立”同一商品的两种表达”之间的等价关系,而不是把 SID 当作与文本完全无关的符号。
-
对齐任务(Alignment Tasks)
① SID–文本语义对齐(双向)
- 给定一个 SID,预测对应商品的文本标题
- 给定一个文本标题,预测对应商品的 SID
Input: What is the title of <a_24><b_141><c_73>? Output: Oral-B Deep Sweep Toothbrush Input: Which item has the title "Nashua Stretch & Seal Self-Fusing Silicone Tape"? Output: <a_202><b_202><c_29>② 商品描述重建 给定一段商品描述,预测对应 SID;反之给定 SID,生成商品描述。由于描述空间开放且多样,该任务仅在 SFT 阶段使用,不延续到 RL 阶段。
③ 用户偏好摘要
给定一段用户的 SID 交互历史,生成一段自然语言描述该用户的兴趣偏好。由于数据集中没有现成的偏好标签,论文使用 DeepSeek 从商品元数据和用户评论中抽取伪标签作为监督信号。同样仅限于 SFT 阶段。
Input: 用户历史 <a_39><b_41><c_1>, <a_39><b_28><c_16>, ... Can you summarize the user's preference? Output: This user has a clear preference for durable, high-performance practical supplies for hands-on tasks...
GRPO
SFT 阶段让模型学会了基本的推荐能力,但其优化目标是模仿训练数据的分布,并不直接优化排序质量。GRPO 阶段的目的是在 SFT checkpoint 基础上,通过强化学习进一步让模型学会区分好坏候选、提升排序精度和候选多样性。
将 GRPO 用于推荐场景面临两个独特障碍,MiniOneRec 分别给出了针对性的设计:
-
挑战一:采样多样性不足
问题:推荐的动作空间是一个封闭的 SID 集合,规模远小于自然语言词表。对同一个 prompt 多次采样,模型往往反复生成相同的商品,导致候选中有大量重复,模型几乎观察不到有效的负样本,训练信号极度稀疏。
解决方案:Beam Search 结合Constrained Decoding:在每一步生成时,屏蔽所有不合法的 token,确保每条 beam 最终都能映射到一个真实存在的商品,从而保证奖励计算的可行性。
-
挑战二:奖励信号稀疏
问题:标准 GRPO 使用二值奖励——命中目标商品得 1 分,其余全为 0。这种设计把所有负样本一视同仁,而实际上模型对不同负样本的置信度差异很大,高置信度的错误(即模型最倾向于推荐却是错的)应该受到更强的惩罚,否则排序质量难以提升。
解决方案:混合奖励
最终奖励由两部分相加构成:$R(e_k,e_t)=R_{rule}(e_k,e_t)+R_{rank}(e_k,e_t)$ ① 规则奖励(ACC Reward):标准二值信号 \(R_{rule}(e_k,e_t)= \begin{cases} 1, & e_k=e_t \\ 0, & \mathrm{otherwise} \end{cases}\) ② 排序感知奖励(Rank Reward):对生成概率排名靠前的负样本施加更强惩罚。设负样本 $e_k$ 在模型输出中的概率排名为 $\rho_k$($ρ$=1 表示最高概率): \(\tilde{R}_{rank}(e_k,e_t)= \begin{cases} 0, & e_k=e_t \\ -\frac{1}{\log(\rho_k+1)}, & \mathrm{otherwise} \end{cases}\) 归一化后即为最终 $R_{rank}$。排名越靠前($\rho_k$ 越小),惩罚越大,迫使模型主动识别并压制那些”自信但错误”的推荐。
复现
RQ-VAE
严格按照 MiniOneRec 原始设置,使用 Qwen3-Embedding-4B 得到的文本嵌入作为原始数据进行训练,具体参数设置如下:
| 数据集 | Industrial_and_Scientific |
|---|---|
| 总 epoch | 10,000 |
| Batch size | 20,480 |
| 优化器 | AdamW,lr=1e-3,weight_decay=0 |
| LR scheduler | constant(前 50 epoch warmup) |
| 损失函数 | MSE + commitment loss(β=0.25)+ per-level VQ loss |
| quant_loss_weight | 1.0 |
| Codebook 结构 | 3 级,每级 256 个码字,code dim=32 |
| MLP 层结构 | [2048, 1024, 512, 256, 128, 64](encoder/decoder 对称) |
| KMeans 初始化 | 开启,100 次迭代 |
训练后,选择最优检查点(epoch 8599)作为最终结果,结果如下:
| 指标 | 值 |
|---|---|
| Total loss | 0.2402 |
| Recon loss | 0.1096 |
| Level 0 VQ loss | 0.2590 |
| Level 1 VQ loss | 0.0859 |
| Level 2 VQ loss | 0.0472 |
| Collision rate | 9.41%(220 个冲突组,347 个 item 非唯一) |
| Codebook 利用率 | L0: 88/256,L1: 256/256,L2: 256/256 |
根据原文设置,还需要进行碰撞处理,进行了 20 次 Sinkhorn 后处理后,碰撞率从 9.41% 下降到了 0.33%。
下面对训练过程的损失函数、碰撞率和码本利用率可视化:
-
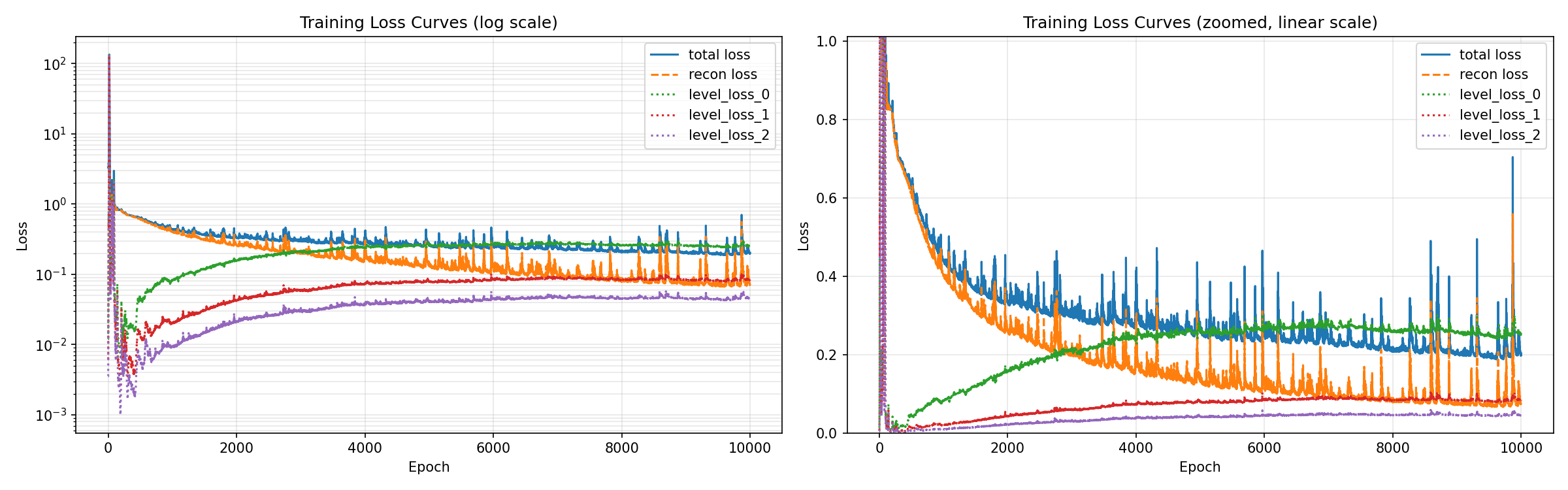
Loss 曲线:总 loss 从训练初期快速下降,在 2000 epoch 后趋于平稳,但有较大振荡(见图中毛刺)。Recon loss 在后期占主导。
-
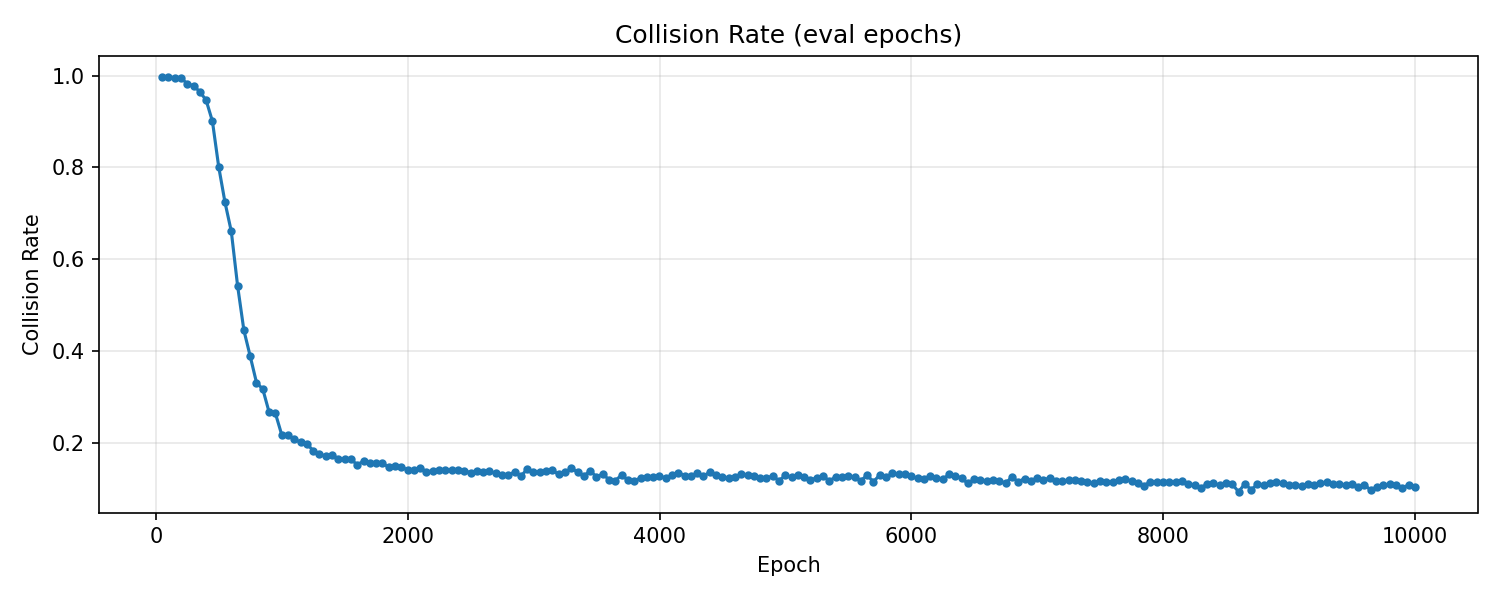
Collision rate 曲线:从初始 ~1.0 急剧下降至 epoch ~2000 时的 ~0.15,之后缓慢改善至 10% 左右,epoch 8599 是 collision 最低点。
-
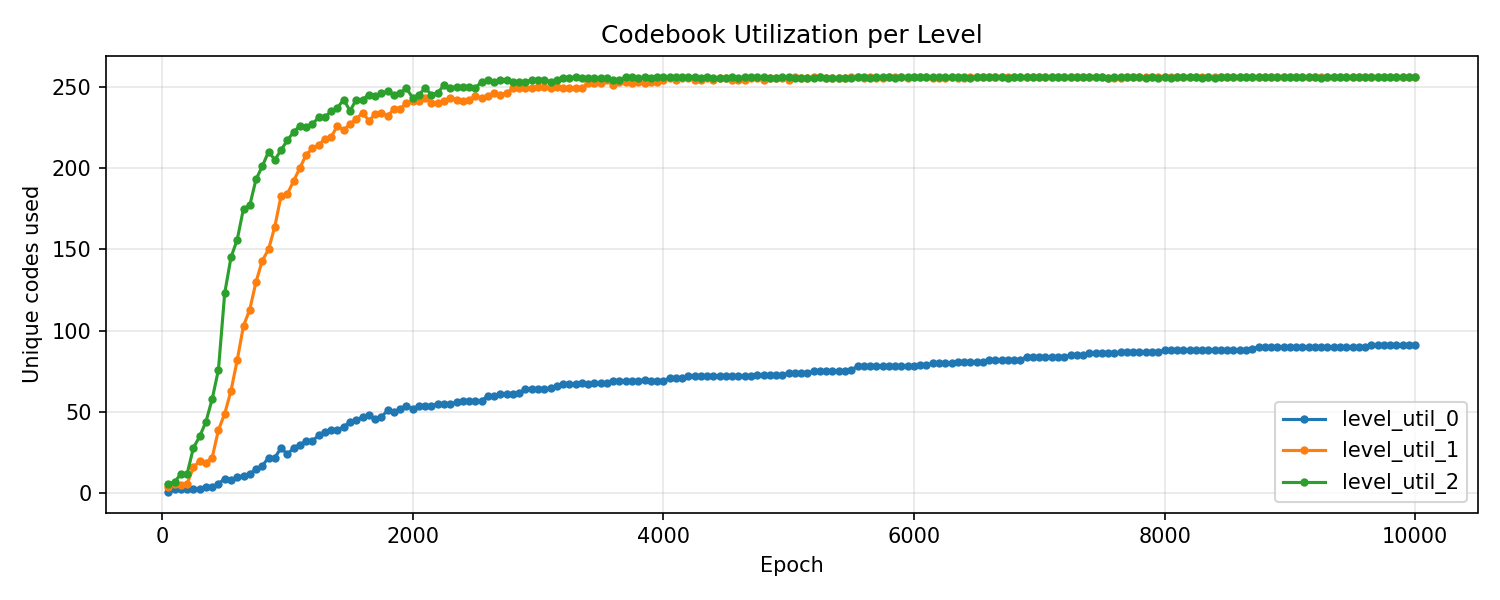
Codebook 利用率:L1、L2 层在约 4000 epoch 时达到近满利用(256/256),但 L0 层只用到 ~91/256 个码字(~35%),表明大多数 item 在第一级量化时聚到少量码字上,第二、三级再做细粒度区分。
SFT
训练的基础设置:
| 参数 | 值 |
|---|---|
| 基座模型 | Qwen2.5-7B-Instruct |
| GPU | Quadro A6000 48GB x2 |
| 数据集 | Industrial_and_Scientific |
| 总 batch size | 256(2 GPU DDP) |
| 优化器 | AdamW,bf16 |
| Warmup steps | 20 |
| Eval 频率 | 每 5% epoch 一次 |
| Early stopping | patience=3 |
| max_len | 512 tokens |
| Beam search(推理) | num_beams=50 |
根据 MiniOneRec 在 Github 开源的训练脚本,实际训练过程中,并没有用到文中提到的所有 SFT 训练集,这里遵循 Github 脚本设置,SFT 训练时使用了如下几种数据集:
-
SidSFTDataset— 主任务:SID 历史序列 → 预测下一个 SID -
SidItemFeatDataset— 对齐任务:SID ↔ 商品文本语义对齐 -
FusionSeqRecDataset— 辅助任务:标题历史序列 → 预测下一个 SID
但验证集只用主任务(SidSFTDataset)。
训练配置及结果:
- LoRA r=64,alpha=128,target 全部注意力+FFN 层
- lr=3e-4,batch_size=256,micro_batch_size=8
- Best eval loss 1.5737,epoch 3.0(early stopping)
| 指标 | 值 | MiniOneRec 原文参考值 |
|---|---|---|
| HR@1 | 0.0735 | - |
| HR@5 | 0.1154 | 0.1321 |
| HR@10 | 0.1405 | 0.1586 |
| HR@20 | 0.1694 | - |
| HR@50 | 0.2305 | - |
| NDCG@1 | 0.0735 | - |
| NDCG@5 | 0.0953 | 0.1084 |
| NDCG@10 | 0.1035 | 0.1167 |
| NDCG@20 | 0.1108 | - |
| NDCG@50 | 0.1229 | - |
使用 LoRA 复现的结果略微劣于原文经过 SFT + GRPO 的完整模型,但优于原文给出的一系列 baseline ,这是一个比较合理的结果。
附上原文中的 baseline 和 MiniOneRec 结果 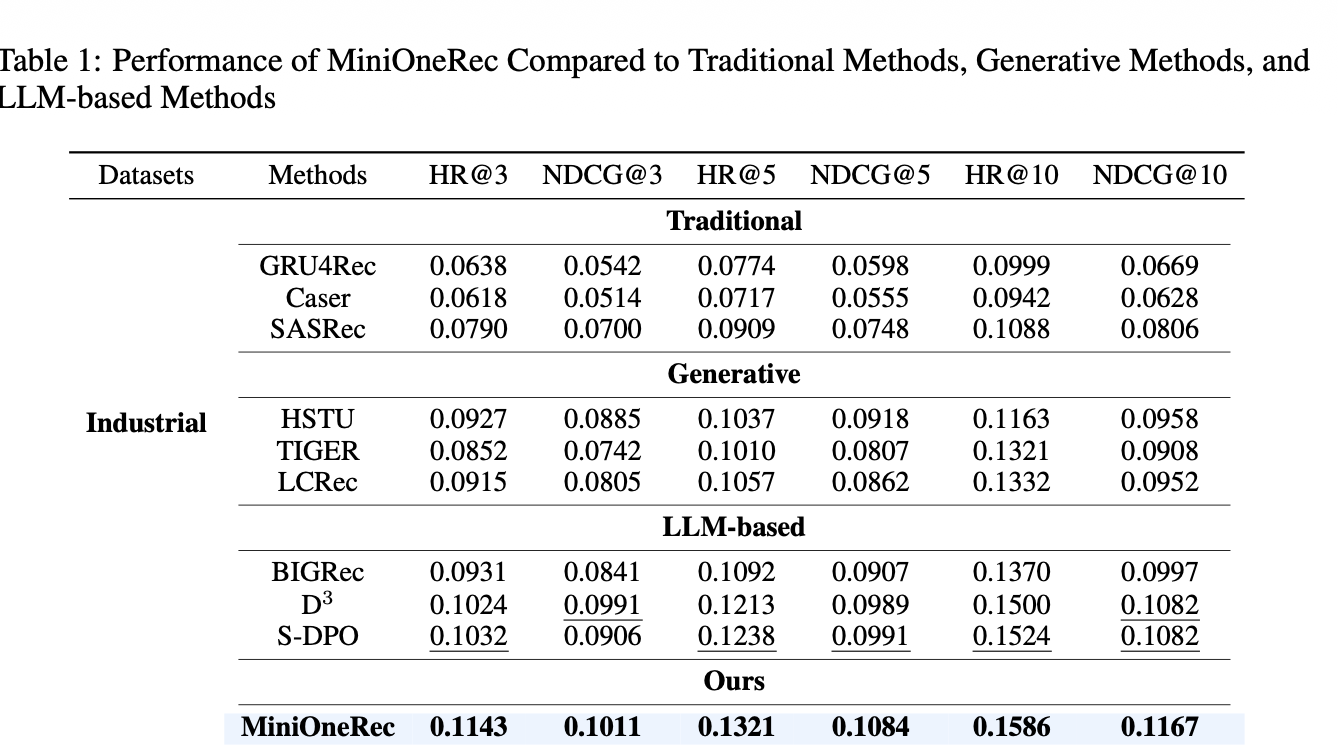
GRPO
参数配置:
| 参数 | 值 |
|---|---|
| 基座模型 | LoRA 合并后的 Qwen2.5-7B(SFT checkpoint) |
| GPU | Quadro A6000 48GB x2 |
| 框架 | TRL GRPOTrainer (修改了一部分逻辑) |
| 精度 | bf16 |
| Epochs | 2 |
| lr | 1e-5(cosine scheduler,warmup_ratio=0.03) |
| 优化器 | paged_adamw_32bit |
| per_device_train_batch_size | 64 |
| gradient_accumulation_steps | 128 |
| num_generations | 16(每条 prompt 采样 16 个候选答案) |
| temperature | 1.0 |
| max_completion_length | 128 |
| beta | 1e-3(KL 散度惩罚系数) |
训练数据
| 数据集类 | 任务 |
|---|---|
SidDataset | 主任务:SID 历史序列 → 预测下一个 SID |
RLTitle2SidDataset | 对齐任务:商品标题 → SID(全量) |
RLSeqTitle2SidDataset | 辅助任务:标题历史序列 → 预测下一个 SID(采样 10000 条) |
验证集只用 SidDataset(主任务)。
训练结果
训练过程可视化:
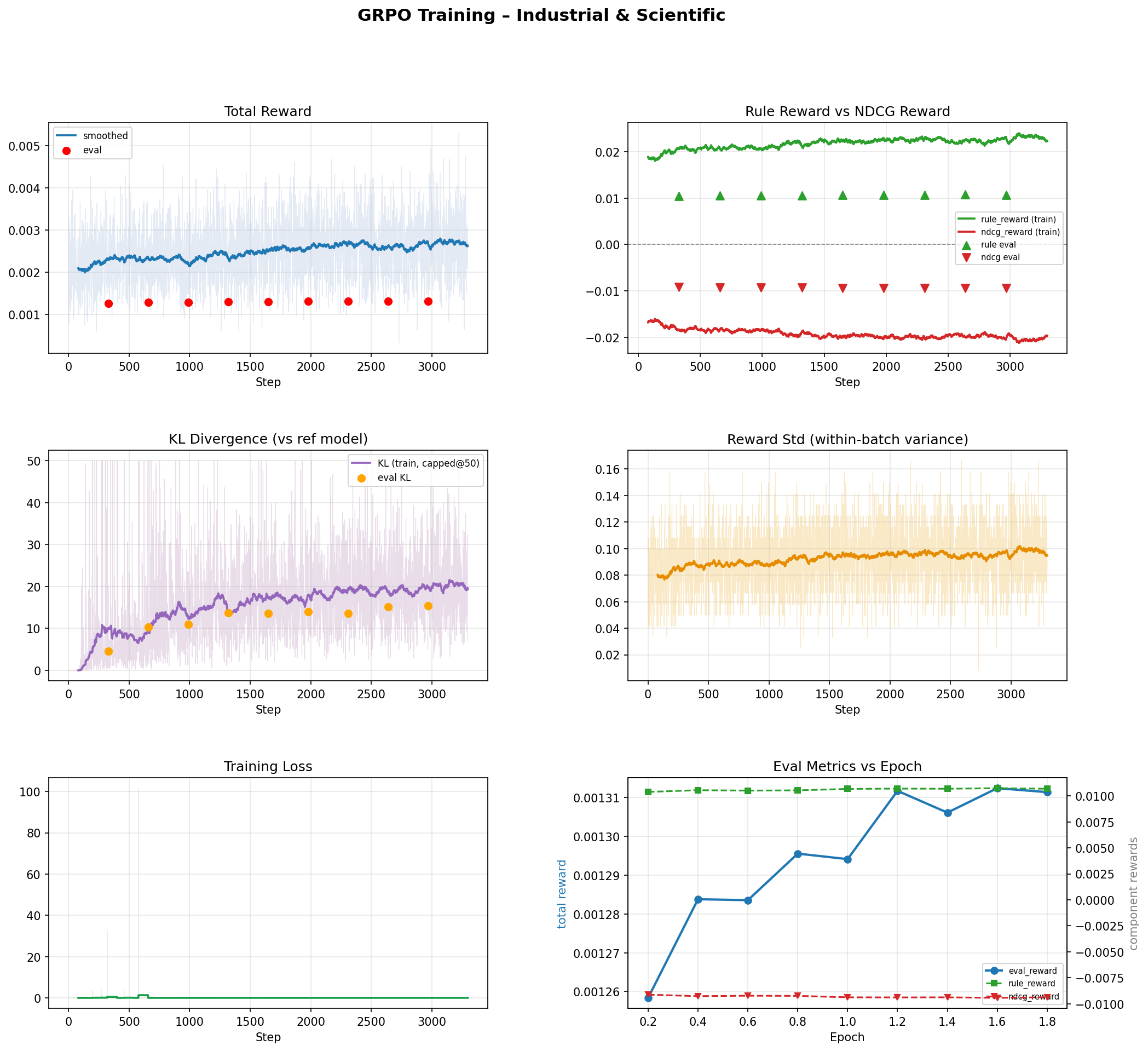 从图中可以观察到几个关键现象:
从图中可以观察到几个关键现象:
- Total Reward(左上:训练 reward 有轻微上升趋势(smoothed 曲线从 ~0.0012 升至 ~0.0030),但 eval 红点始终在低位(~0.0013),说明训练集上学到的东西在 eval 上转化有限。
- Rule vs NDCG Reward(右上):rule_reward(绿)稳定正值 ~0.01-0.02,ndcg_reward(红)始终为负 ~-0.01,两者全程几乎没有变化——印证了训练中奖励信号极弱的问题。
- KL Divergence(左中):从 0 单调上升到 ~20-30,模型持续偏离 ref model,但奖励没有跟上,说明策略在”探索”但学到的不一定对。
- Training Loss(左下):注意 y 轴到了 100,出现了多个极端峰值——这是 KL 剧烈震荡时 penalty 项爆炸导致的,与 KL 曲线的尖峰对应。
- Eval Metrics vs Epoch(右下):eval_reward 从 epoch 0.2 到 0.4 有一次小幅跳升,之后趋于平稳。整体改善幅度与最终 NDCG 提升(~4-6%)一致,只是代理指标不够直观。
对 GRPO 训练后的模型重新在测试集上评估:
| 指标 | SFT lora_merged(起点) | GRPO merged | 变化 |
|---|---|---|---|
| NDCG@1 | 0.0735 | 0.0774 | +5.4% |
| NDCG@5 | 0.0953 | 0.0986 | +3.5% |
| NDCG@10 | 0.1035 | 0.1081 | +4.4% |
| NDCG@20 | 0.1108 | 0.1164 | +5.0% |
| HR@1 | 0.0735 | 0.0774 | +5.4% |
| HR@5 | 0.1154 | 0.1178 | +2.1% |
| HR@10 | 0.1405 | 0.1469 | +4.6% |
| HR@20 | 0.1694 | 0.1798 | +6.1% |
| HR@50 | 0.2305 | 0.2301 | ≈0 |
- NDCG@1~@20 和 HR@1~@20 全部改善 2-6%,说明模型在 top-K 的排序质量上确实学到了东西
- HR@50 几乎持平(-0.2%),说明”召回覆盖率”没变,GRPO 的收益主要来自把正确答案推到更靠前的位置
- 训练日志中奖励信号很弱,但 beam search 评估指标出现了一致性提升,说明 GRPO 仍然有效地在优化正确的方向
原文并没有做直接去掉 GRPO 过程的 ablation study,所以无法得知原文中 RL 阶段对模型性能的提升幅度。但总体来看,在我的复现工作中,虽然训练过程中 reward 几乎没有可见上升,但最终的 NDCG/HR 改善是真实的。
总结
完整复现了 MiniOneRec 的完整 pipeline,包括重新训练 RQ-VAE 编码器,并以 Qwen2.5-Instruct-7B 为基座,依次完成了 SFT 与 GRPO 训练。 从 HR 和 NDCG 两项指标来看,复现结果与原文略有差距,但考虑到训练时未严格对齐原文的 batch size、learning rate 等超参数设置,且重训的 RQ-VAE 与原文亦存在差异,这一偏差在合理预期之内。
总体而言,复现结果成功验证了 MiniOneRec 的核心主张:将推荐任务与 LLM 对齐训练所构建的新一代生成式推荐系统,确实能取得较为理想的效果;GRPO 对模型性能的提升作用也得到了印证。
至于原文关于生成式推荐系统可受益于 scaling law 的主张,由于本次复现仅覆盖 7B 规模,暂无法直接验证。不过,结合原项目 GitHub Issue 中的相关讨论,其他研究者在更小规模模型上的实验结果确实弱于 7B,间接为该主张提供了一定支撑。